Usando Métricas em Gestão de Engenharia de Software
Princípios para medir da forma certa
Esse post foi traduzido automaticamente do inglês. Se você encontrar algum erro, por favor entre em contato.
 Inspecionando código, por MidJourney
Inspecionando código, por MidJourney
Existe muita informação no desenvolvimento de software. Times rastreiam seus tickets com sistemas de software. Registramos cada commit de código. Todas as operações primárias ao longo do ciclo de vida do software, incluindo releases, testes e operações, têm múltiplas métricas associadas a elas.
Com tudo isso, é um tanto surpreendente que métricas não tenham sido mais importantes para Engineering Managers (EMs) recentemente. Olhando para a última década, as principais métricas que EMs usavam consistentemente seriam velocidade e algum tipo de estimativa de ticket. Mas isso mudou rapidamente, e agora a indústria está se apressando para descobrir como melhorar a efetividade com todos os dados que se tornaram disponíveis de repente.
A Era de Ouro das Métricas
Métricas voltaram ao mainstream da gestão quando as métricas DORA conectaram algumas medições a times altamente efetivos. Mais recentemente, as métricas SPACE apresentaram uma abordagem para pensar sobre produtividade de desenvolvedores. E na esteira disso, parece que uma centena de ferramentas de rastreamento de engenharia de software apareceram no mercado.
Esse movimento em direção à gestão de engenharia de software orientada por dados tem grande potencial de ser positivo e levar times a melhores resultados. Ainda é surpreendente quantas decisões que envolvem muito esforço e recursos são tomadas principalmente com base em opiniões. Por exemplo, muitos projetos significativos de refatoração ou reconstrução que vi (e liderei!) foram baseados em opiniões subjetivas de que algum código não era bom o suficiente. Infelizmente, como um velho amigo costumava dizer, “existem dois tipos de código: código bom e código que você não escreveu.” Ter métricas disponíveis para melhor tomada de decisão pode ser um passo significativo em direção a organizações de engenharia de software mais produtivas.
No entanto, sempre existem riscos e desafios ao adotar métricas. Elas iluminam áreas específicas do ambiente de trabalho ao mostrar às pessoas como uma parte específica está indo. Se não formos cuidadosos ao adotá-las, podemos destacar as áreas erradas, criando comportamentos improdutivos e às vezes até prejudiciais.
Diga-me Como Você Me Mede
O principal desafio é que organizações são direcionadas por métricas e pelo que pode ser medido. Se existem métricas disponíveis, agora existem oportunidades de otimização. Por exemplo, resultados anuais e trimestrais e avaliações de performance são orientados por métricas. Disponibilizar métricas para uma característica específica frequentemente levará a esforços para analisá-la e otimizá-la.
“Diga-me como você me mede e eu te direi como vou me comportar.” — Eliyahu M. Goldratt
E isso pode levar a alguns antipadrões:
Usar métricas como ferramenta principal para avaliar indivíduos
Esse é o antipadrão mais discutido. Parece ultrapassado continuar repetindo que não devemos medir esforços de engenharia com base em linhas de código (LoC). E embora LoC (quase) não seja mais discutido, agora falamos sobre número de Pull Requests (PRs), número de commits e muitas outras métricas baseadas em output.
Métricas vão direcionar o comportamento individual. Se você avalia engenheiros com base em PRs, engenheiros vão escrever mais PRs. E espero que entendamos que ter mais código nunca é a solução. Frequentemente é o problema.
Focar em métricas individuais
Além de avaliar pessoas, vale destacar que simplesmente ter métricas disponíveis vai direcionar as pessoas a melhorá-las. Métricas individuais podem ser positivas, mas também vão direcionar comportamento indesejado em um time. Se um time regularmente revisa métricas individuais, isso direciona comportamento individualista, frequentemente prejudicando o output do time.
Um exemplo simples é olhar para a agora popular medição de tempo de ciclo de PR. Se o que um time mede é o tempo de ciclo individual (ou seja, tempo para abrir e fechar um PR), engenheiros vão abrir e fechar PRs o mais rápido possível. Isso é ótimo, em teoria, a menos que outros engenheiros estejam esperando por um code review no seu PR mas não consigam encontrar ajuda porque todos estão tentando resolver seu próprio problema primeiro.
Foco excessivo em eficiência
O desafio menos visível (e, na minha opinião, mais prejudicial) com métricas é o foco em eficiência que elas trazem. Em outras palavras, métricas tornam mais fácil gerar mais output, mesmo com o resultado errado.
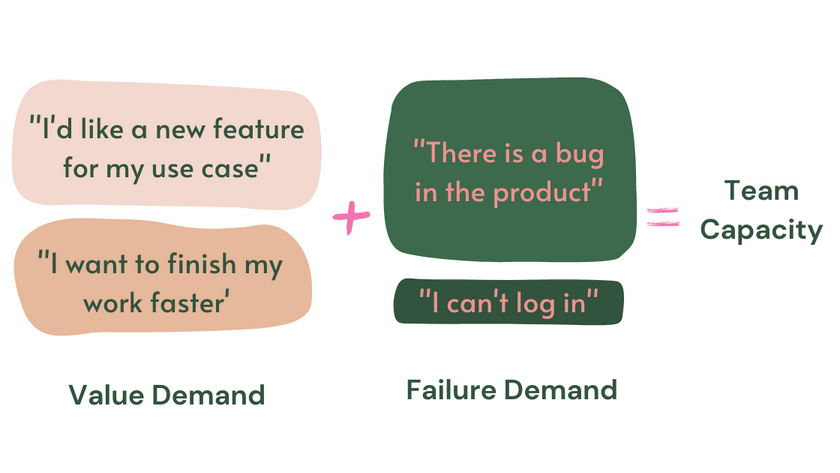
A base desse problema é que uma quantidade significativa de trabalho em qualquer organização nunca deveria ser feita e não entrega valor. Entender esse problema é o pensamento por trás de desperdício em Sistemas Lean, KTLO na discussão atual de engenharia de software, ou demanda de falha. São todos conceitos similares que dizem uma coisa: uma parte do trabalho que os times fazem não tem valor.
 Desperdício no trabalho
Desperdício no trabalho
Um exemplo recorrente é como times às vezes focam demais em métricas de tempo de resolução de bugs/incidentes, criando uma perspectiva de que “corrigir bugs rapidamente” cria valor para o cliente quando, na realidade, não ter os bugs em primeiro lugar seria muito mais apreciado.
De Olho no Objetivo
Com todos os desafios acima em mente, vale lembrar que métricas podem ser benéficas desde que os times as usem para melhorar como chegar aos resultados desejados. Em outras palavras, EMs precisam aplicar métricas que os ajudem a melhorar o sistema de trabalho, levando a melhores resultados para seus times.
Ao fazer isso, existem alguns princípios que tento manter em mente nos times que ajudo a gerenciar:
Entender trabalho de valor e trabalho sem valor
O passo essencial em qualquer medição que um time pode fazer é entender o que é trabalho de valor e trabalho sem valor, e quanto de cada o time executa. Claro, existem diferentes formas de olhar para valor. Mas uma forma simples de defini-lo é qualquer coisa que um cliente vai apreciar (novas funcionalidades, melhor performance, mais estabilidade), com tudo mais sendo considerado desperdício (corrigir bugs, lidar com incidentes, refatorar código de baixa qualidade).
Sempre haverá uma quantidade de trabalho sem valor necessária, mas os times devem focar em eliminá-lo em vez de se tornar eficientes em lidar com ele.
Pensar sobre o fluxo de trabalho
Embora métricas específicas de processo como tempo de ciclo de PR, MTTR e tempo de code review sejam úteis, times devem usá-las para melhorar o fluxo geral de trabalho, não isoladamente. Em outras palavras, times devem entender o sistema geral primeiro (ou seja, quão rápido conseguimos entregar um projeto ou funcionalidade da ideia à produção), para então avançar para métricas mais direcionadas para otimização.
Reduzir o tempo de ciclo de PR só faz sentido se ajudar a reduzir o tempo geral de entrega de valor. E os times precisam entender a métrica mais ampla para tomar decisões ao redor dela.
Entender causas especiais e causas comuns
Ao olhar para métricas recorrentes, também é importante entender que todo processo tem variações e a diferença entre causas especiais e causas comuns. Em um time de software, por exemplo, o tempo de ciclo para PRs serem mergeados terá uma variação natural baseada na complexidade e em como o time trabalha.
Não é incomum ver times agindo sobre métricas como se elas devessem ser estáveis, tomando ações e consumindo esforço em áreas que não levarão a melhoria. No exemplo acima, times deveriam focar em causas comuns para reduzir essa variação (ou seja, quanto tempo leva para PRs serem revisados) em vez de agir sobre outliers (ou seja, nesse sprint, o tempo de ciclo subiu porque alguém estava doente).
Estabilize. E então melhore
Por fim, entenda que métricas com alta variabilidade serão impossíveis de melhorar. Por exemplo, suponha que seu tempo de ciclo varia de 1 a 30 dias. Nesse caso, qualquer melhoria que um time tente nessa área será difícil de perceber, levando a um ciclo de melhoria de processos improdutivo, com muitas ideias e esforço para melhorar as coisas, mas sem resultados reais.
O primeiro passo para qualquer esforço de melhoria é estabilizar uma métrica, ou seja, reduzir a variação para um nível estável. No exemplo acima, se o tempo de ciclo de tickets varia significativamente, o primeiro passo seria reduzir a variação no tamanho de cada ticket, garantindo que os tickets sejam divididos em partes de esforço similar. Uma vez que isso seja alcançado, será muito mais fácil experimentar melhorias e entender se elas são bem-sucedidas.
Métricas vieram para ficar
Métricas não vão a lugar nenhum na engenharia de software, e continuarão sendo adotadas com mais frequência conforme mais ferramentas e dados de suporte se tornam disponíveis para os times consumirem.
Nesse contexto, EMs devem focar em aplicar as melhores métricas para seu time de acordo com sua situação, em vez de simplesmente adotar o que foi oferecido porque alguém decidiu comprar um software de rastreamento específico. Fazer da forma certa levará a muito mais visibilidade na execução e resultados para seus times.
Esse post faz parte de uma série sobre Liderando Times de Software com Pensamento Sistêmico.
Comentários