Diga-me Como Você Me Avalia
Uma visão prática de métricas de engenharia de software
Esse post foi traduzido automaticamente do inglês. Se você encontrar algum erro, por favor entre em contato.
Em um dos meus últimos posts, mencionei métricas como uma ferramenta que uso para gerenciar tanto para cima quanto para baixo. Desde então, recebi algumas perguntas sobre quais métricas costumo acompanhar e como as utilizo. Métricas são uma parte essencial da gestão de engenharia para mim, então aqui estão os detalhes.
Por Que Métricas?
Além do usual “você não pode gerenciar o que não mede”, métricas estão se tornando mais relevantes na indústria, especialmente após o lançamento do Accelerate.
Existe uma oportunidade de usar métricas mais na gestão de engenharia. Acredito que essa mudança começou quando a indústria passou a focar na gestão de indivíduos em vez de times, mas esse é mais um tema para outro post. Quando bem aplicadas, métricas podem ser usadas para influenciar comportamentos e alinhar positivamente o time, tanto os indivíduos quanto o grupo.
Aqui estão alguns exemplos de como:
Para trazer ajuda. Eu já fui engenheiro e já vi muitos engenheiros trabalhando. Ficar preso em rabbit holes é algo real. Se você entende seu cycle time médio, pode identificar outliers conforme acontecem. Isso permite que você intervenha com suporte e ajuda quando as pessoas precisam.
Para melhorar o foco. Todos os times com os quais trabalhei são repletos de interrupções. Podem ser defeitos, plataformas legadas ou projetos especiais acontecendo em paralelo. Medir onde seu tempo está sendo gasto pode ajudar a navegar melhor pelas distrações.
Recentemente analisei um dos meus times ao longo de seis meses para identificar nosso foco. Descobri que tínhamos gasto 50% do nosso tempo em projetos que não se alinhavam com nossos objetivos. Estávamos ocupados trabalhando na manutenção de sistemas legados e executando diferentes projetos especiais. Difícil atingir aquelas metas quando metade dos seus esforços estão mal direcionados.
Para melhorar a eficiência. Quando você associa o cycle time a partes específicas do sistema, consegue identificar pontos que precisam de atenção. Entender os hotspots de manutenção é uma informação valiosa no trabalho de suporte. Isso ajuda a decidir se vale a pena melhorar um sistema ou deixá-lo como está.
Já usei dados de defeitos tanto para gerenciar para cima quanto para baixo em diferentes situações. Para cima quando pedindo tempo para refatorar um sistema específico com problemas, e para baixo quando alinhando com engenheiros sobre por que devemos/não devemos refatorar um sistema.
O Que Medir?
Uma vez que você sabe como o acompanhamento pode ajudar, a próxima pergunta é: o que você deve acompanhar? Começo dizendo que minhas sugestões abaixo não são exaustivas. A seguir está um conjunto de medições que achei úteis.
Velocidade
A métrica básica, se você usa estimativas em story points. Geralmente meço iteração por iteração e a média das últimas três iterações. Dado que não sou fã de trabalho rígido em sprint, me preocupo menos com o que acontece a cada semana e mais com a tendência.
Além de notar e discutir quando há variação considerável de uma iteração para outra, o propósito principal da velocidade para mim é permitir melhor previsibilidade.
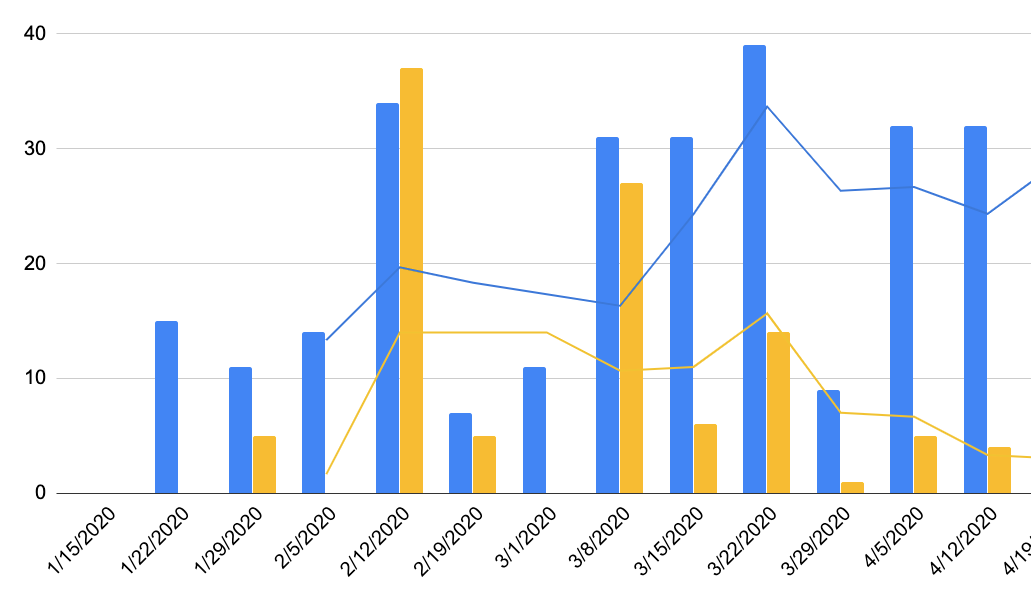 Velocidade semana a semana para dois times diferentes
Velocidade semana a semana para dois times diferentes
Cycle Time
Meço a distribuição do cycle time em uma média por ponto entre todas as features, e para cada tamanho de história (1, 2 e 4 no nosso caso).
Isso torna tendências visíveis (estamos ficando mais rápidos ou mais lentos no geral). Também uso para identificar outliers e refletir sobre eles. Quando outliers acontecem, você pode analisar se há melhorias possíveis a serem feitas, tanto na execução quanto na estimativa.
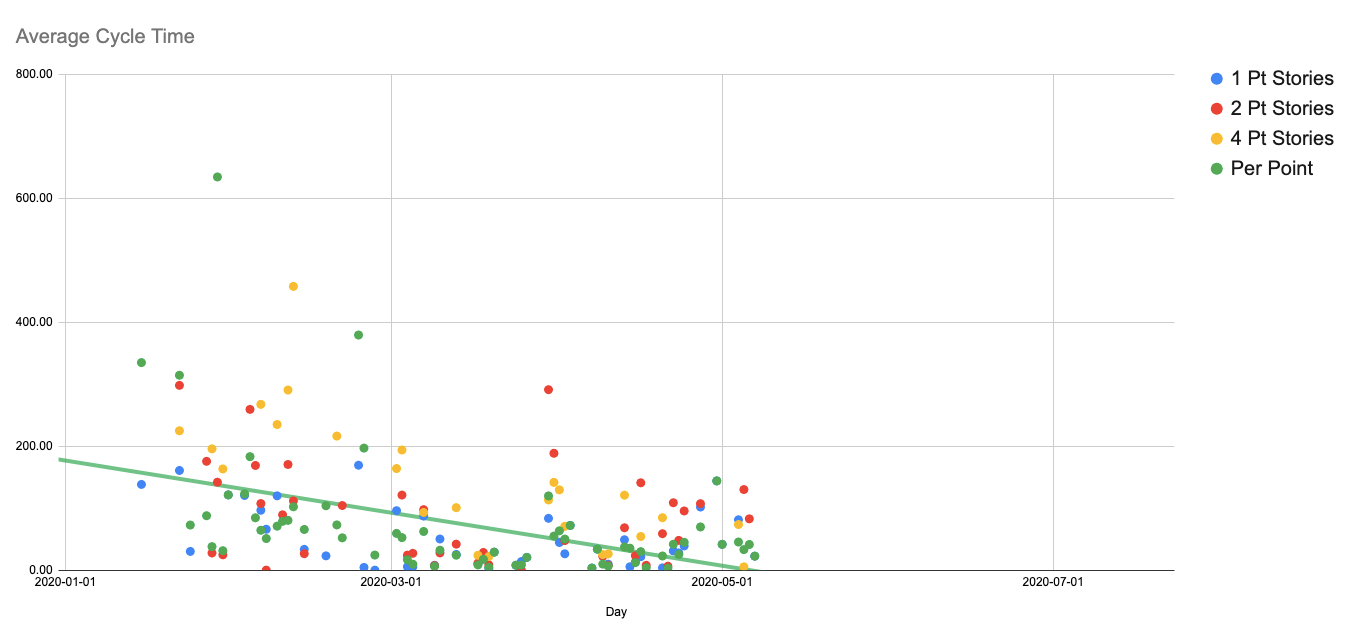 Médias de cycle time por dia e tamanho
Médias de cycle time por dia e tamanho
Tempo Gasto em Features, Chores e Defeitos
Medição de porcentagens agregadas de cycle time para cada tipo de trabalho. Achei isso útil para gerenciar para cima e mostrar por que resultados específicos aconteceram.
Por exemplo, nas duas primeiras semanas de fevereiro, tínhamos um prazo de mercado apertado e entregamos sob pressão. A consequência fica aparente quando olhamos para a porcentagem de trabalho com defeitos nas duas semanas seguintes. Caímos abaixo de padrões de qualidade aceitáveis.
Tempo Gasto em Projetos
Mesma métrica acima, mas segmentada por projetos. Útil para entender onde o esforço do time está indo e refletir sobre isso.
Criticidade de Defeitos
Defeitos reportados e corrigidos, e uma pontuação baseada no número e criticidade dos problemas reportados em uma semana específica. Essa métrica é uma adição recente e tem sido útil para entender a qualidade que estamos entregando semana a semana.
Como Obter Esses Dados?
Como você pode notar, as métricas acima são todas extraídas do nosso software de gestão e plotadas no Excel. Outras ferramentas prontas podem automatizar métricas e visualização com o software que você já usa.
Não é uma lista exaustiva, mas algumas opções que já analisei. Não usei nenhuma delas, porém, então não posso fornecer informações mais detalhadas.
-
Nave: Métricas Kanban extraídas do seu software de gestão. Fornece algumas das métricas mencionadas acima, além de outras. Parece uma opção útil, embora eu ainda não tenha experimentado.
-
Pinpoint: A mais próxima do que eu estava procurando — focada em gestão de time e insights com métricas do seu software de gestão e controle de código fonte. Adiciona IA para fornecer previsões baseadas nos seus dados passados.
-
Velocity: Insights de time baseados em análise de controle de código fonte. Informações interessantes, mas baseadas em Pull Requests, o que faz menos sentido para mim.
Comentários